,allowExpansion)
Language2code
Come generare codice utilizzando l’intelligenza artificiale
Language-to-code: di cosa si tratta?
Con l’espressione “language-to-code” si fa riferimento ai modelli di intelligenza artificiale che consentono di interpretare istruzioni in linguaggio naturale e generare del codice che rispetti tali istruzioni. Il principale è Codex, rilasciato da OpenAI, ma tutti i leader del settore (inclusi Google, Meta e Facebook) hanno sviluppato o prevedono di sviluppare modelli di questo genere.
Questi modelli possono essere applicati a diversi casi d’uso:

Generazione automatica di documentazione a partire dal codice

Completamento automatico di un blocco di codice

Traduzione di codice da un linguaggio ad un altro

Refactoring e correzione automatica
di errori

Scrittura automatica di unit test

Generazione automatica di codice a partire da una descrizione in linguaggio naturale
Come funziona un motore di language-to-code
I motori di language-to-code sono implementati come transformer language model: reti neurali appositamente addestrate per lavorare sul testo e per comprendere il linguaggio naturale. In questo senso, questi modelli trattano il codice come una forma di linguaggio, seguendo il paradigma left-to-right: agiscono ricevendo un blocco di testo come input (il cosiddetto “prompt”) e restituendo il testo che identificano come più adatto a completare quanto fornito.
Questi modelli sono spesso “preaddestrati”: i parametri che determinano il risultato della loro esecuzione sono stati determinati analizzando una grossa mole di dati, come ad esempio grandi repository pubblici di codice sorgente. I modelli più avanzati attualmente disponibili hanno una dimensione superiore alla decina di miliardi di parametri.
La dimensione di questi modelli e la mole di dati di addestramento utilizzati, è direttamente proporzionale alla loro efficacia, ma rischia di presentare un problema noto come “overfitting”: un modello è così ben addestrato da rispondere quasi perfettamente a richieste che corrispondono a problemi noti, ma gestisce molto peggio richieste che si discostano dal suo set iniziale di dati. Per evitare questo problema, è necessario un delicato lavoro di ottimizzazione e di taratura per consentire al modello di avere la flessibilità necessaria a renderlo efficace nel maggior numero possibile di situazioni.
Analizzare l’efficacia dei modelli
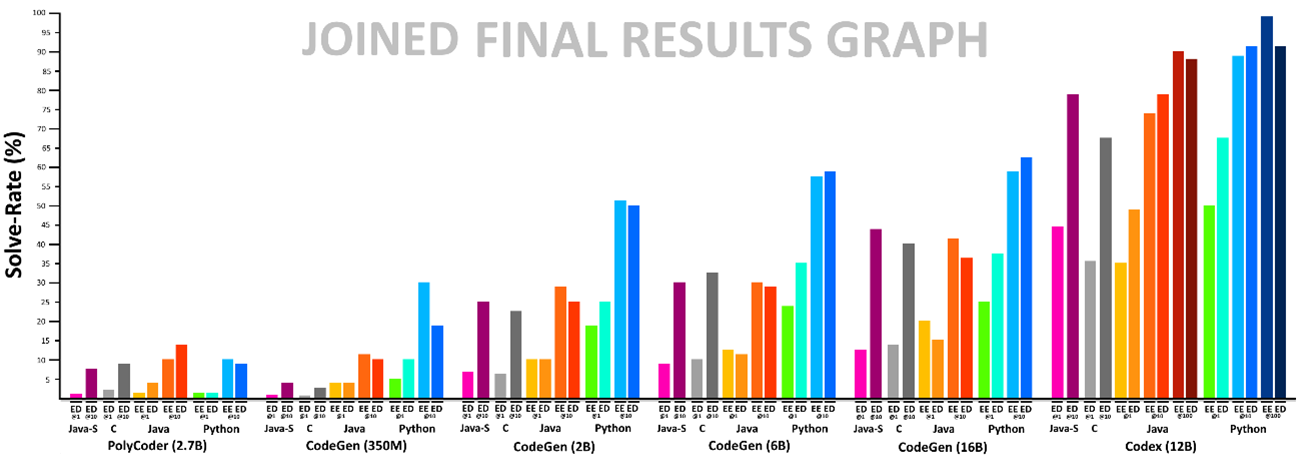
In Reply abbiamo iniziato a testare questi modelli, così da esplorare i diversi casi d’uso di applicazione e valutarne l’efficacia relativa, predispondendo un approccio che consente di analizzare in maniera oggettiva l’efficacia dei vari modelli di language-to-code presenti sul mercato. La procedura è basata su HumanEval, un set di problemi di programmazione pensato per coprire un ampio spettro di casi.
Il test consiste nel sottoporre ai modelli i vari problemi del set ed eseguire il codice generato, verificandone la correttezza: questo test è eseguito più volte, fino a quando non restituisce un risultato corretto. La percentuale di test superati è l’indice dell’efficacia del modello.
Abbiamo inoltre predisposto una variante di questo test che, oltre al testo del problema, fornisce anche alcuni esempi dei risultati attesi. Questa variante tende a favorire i modelli che effettivamente “comprendono” il significato delle richieste, rispetto a quelli che associano la richiesta a un problema noto, sfruttando l’overfitting.
Questo approccio è stata sviluppato per essere estendibile ed applicabile a diversi linguaggi di programmazione e modelli, così da poter facilmente ripetere i test e replicare i risultati anche ai nuovi modelli che emergeranno nel prossimo futuro.
A seguito dell’esecuzione dei test, Codex si è confermato il migliore tra i modelli analizzati, superando in efficacia anche modelli di dimensione maggiore, evidenziando quindi l’efficace processo di taratura a cui è stato sottoposto.
Verifica dell’esecuzione e correzione degli errori
Sulla base dello sviluppo e dell’esecuzione dei test di efficacia, siamo arrivati alla definizione di una procedura che consente di migliorare la correttezza dei processi di generazione del codice a partire dal linguaggio naturale, associando alla descrizione un set di “condizioni di accettazione” che consentono di verificare la correttezza del risultato ottenuto. La generazione del codice è quindi eseguita più volte, finché i test di correttezza non restituiscono esito positivo.
Procedendo in questo modo, è possibile scartare le generazioni errate ed accertarsi automaticamente della correttezza delle procedure senza richiedere verifiche manuali. In Reply stiamo attivamente lavorando su questo approccio, così da supportare i nostri clienti nei test relativi ai loro casi d’uso specifici.