,allowExpansion)
Language2code
Codegenerierung mithilfe von Künstlicher Intelligenz
Language-to-Code: Was ist das?
Mit dem Begriff „Language-to-Code“ werden Modelle Künstlicher Intelligenz bezeichnet, die Anweisungen in natürliche Sprache umwandeln können. Zudem erzeugen diese Modelle auch ausgehend von den Anweisungen den entsprechenden Code. Das wichtigste Modell ist Codex von OpenAI. Doch auch alle anderen Marktführer in diesem Bereich wie Google, Meta oder Facebook haben derartige Modelle entwickelt oder planen dies.
Diese Modelle lassen sich für verschiedene Anwendungsfälle einsetzen:

Automatische Erstellung von Dokumentationen ausgehend vom Code

Automatische Vervollständigung von Codeblöcken

Übersetzung von Code in andere Programmiersprachen

Refactoring und automatische Fehlerkorrektur

Automatisches Schreiben von Testeinheiten

Automatische Codegenerierung durch eine Beschreibung in natürlicher Sprache
Wie funktioniert eine Language-to-Code-Engine?
Language-to-Code-Engines werden als Transformer-Language-Modell implementiert. Dabei handelt es sich um neuronale Netze, die speziell für die Verarbeitung von Texten und das Verständnis natürlicher Sprache trainiert wurden. Im Grunde behandeln diese Modelle den Code als eine Form von Sprache. Dabei wenden sie das Left-to-right-Paradigma an: Sie erhalten einen Textblock als Input, den sogenannten Prompt, und geben den Text aus, der als die am besten passende Ergänzung des eingegebenen Textes erkannt wird.
Diese Modelle sind oft „vortrainiert“: So wurden die Parameter, die das Ergebnis bestimmen, durch Auswertung großer Datenmengen wie öffentlicher Quellcode-Repositories ermittelt. Die derzeit fortschrittlichsten Modelle umfassen mehr als 10 Milliarden Parameter.
Der Umfang eines solchen Modells und die Menge der zum Training verwendeten Daten haben direkte Auswirkungen auf dessen Leistungsfähigkeit. Allerdings besteht das Risiko des Overfitting: Modelle werden so gut trainiert, dass sie praktisch perfekt auf Anfragen zu bekannten Problemen antworten, jedoch Anfragen, die vom ursprünglichen Datensatz abweichen, viel schlechter handhaben. Um dieses Problem zu vermeiden, ist eine spezifische Optimierung und Feinabstimmung erforderlich, damit das Modell die nötige Flexibilität erlangt. Nur so kann es in möglichst vielen unterschiedlichen Situationen zuverlässig funktionieren.
Analyse der Leistungsfähigkeit von Modellen
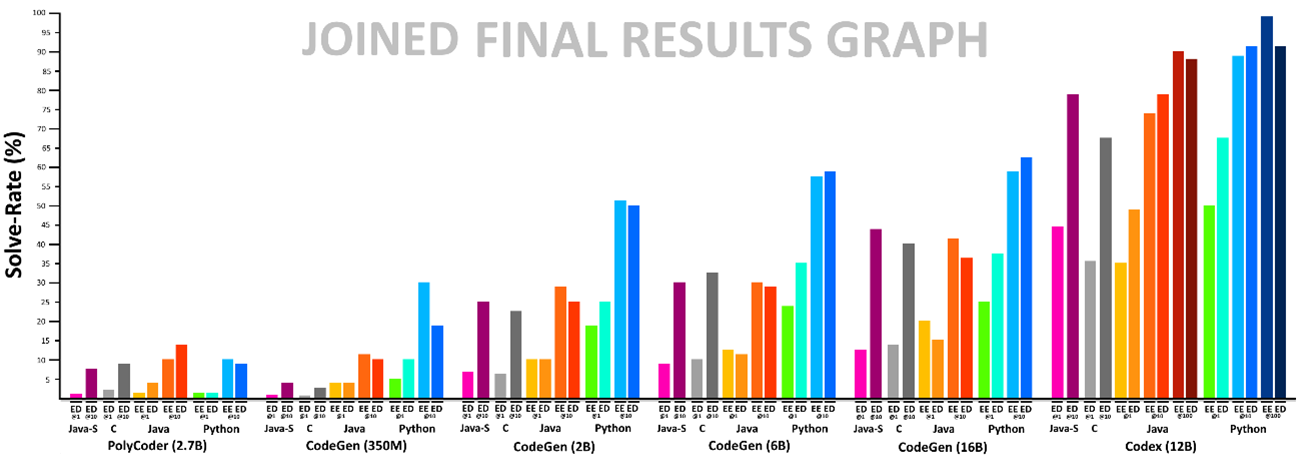
Bei Reply haben wir begonnen, diese Modelle zu testen, um verschiedene Anwendungsfälle zu untersuchen und die entsprechende Leistungsfähigkeit zu bewerten. Dazu haben wir einen Ansatz entwickelt, mit der sich die Leistungsfähigkeit der verschiedenen derzeit am Markt verfügbaren Language-to-Code-Modelle objektiv analysieren lässt. Dieser basiert auf HumanEval, einem Set von Programmierungsproblemen zur Abdeckung einer breiten Palette an Fällen.
Beim Test werden die Modelle mit den verschiedenen im Set enthaltenen Problemen konfrontiert. Der generierte Code wird dann ausgeführt und auf seine Korrektheit überprüft. Dieser Test wird so lange durchgeführt, bis ein korrektes Ergebnis ausgegeben wird. Der prozentuale Anteil der bestandenen Tests gibt die Leistungsfähigkeit des Modells an.
Außerdem haben wir eine Variante dieses Tests entwickelt, die neben dem Text des Problems auch einige Beispiele für die erwarteten Ergebnisse enthält. Bei dieser Variante schneiden Modelle, die die Bedeutung der Anfragen effektiv „verstehen“, tendenziell besser ab als diejenigen, die unter Nutzung des Overfittings die Anfrage einem bekannten Problem zuordnen.
Unser Ansatz wurde so konzipiert, dass sie sich einfach an verschiedene Programmiersprachen und Modelle anpassen lässt. So können die Tests leicht wiederholt und auch auf die neuen Modelle angewendet werden, die künftig entstehen.
In den Tests erwies sich Codex erneut als das beste Modell unter den analysierten Modellen. Es konnte sogar eine höhere Leistungsfähigkeit als umfangreichere Modelle erzielen.
Tests zur Ausführung und Fehlerkorrektur
Durch die Entwicklung und Ausführung der Tests konnte ein Ansatz entwickelt werden, der es ermöglicht, die Codegenerierung zu optimieren. Dieser ist eine Variante der ausgeführten Testverfahren: Der Beschreibung in natürlicher Sprache wird ein Set aus Akzeptanzkriterien zugeordnet, dank der die Korrektheit des erzielten Ergebnisses überprüft werden kann. Die Codegenerierung wird also mehrmals ausgeführt, bis die Korrektheitstests ein positives Resultat ergeben.
Durch dieses Vorgehen können die fehlerhaften Ergebnisse aussortiert werden, so dass ohne manuelle Überprüfungen automatisch die Korrektheit sichergestellt werden kann. Bei Reply arbeiten wir aktiv an diesem Ansatz, um unsere Kunden bei den Tests für ihre spezifischen Anwendungsfälle unterstützen zu können.