)
How synthetic data is revolutionising Industries
Revolutionising Industries with Synthetic Data: How Industries are Leveraging this Game-Changing Technology
AI's Transformative Impact on Business
It’s 2023 - AI has taken off in the last two years with the release of brand-new Large Language Models (LLMs). ChatGPT has caught the imagination of the general public in what possibilities AI generated data has to offer, and now companies are following suit. AI investment is forecast to increase at a compound annual growth rate of 37% (source) from 2023 to 2030. However, it is not always obvious how this technology will directly impact business, with accusations that LLMs are nothing more than toys to experiment with.
What is Synthetic Data?
Synthetic data is a type of generated data which mimics examples of real-world data. It is used as input for analysis and Machine Learning purposes in combination of existing data or without the need to use real-world data. This can be particularly useful when the required data for our analysis is very rarely observed in the real world or when the cost of acquiring this data is too high or the data is too difficult to acquire or process (i.e due to various privacy and regulations).
Some methods for generating synthetic data include 3 methods.
Generative AI for custom Synthetic Data
Furthermore, with the recent advancement in Generative AI; models such as Generative Pre-trained Transformer (GPT), Differential Auto-Encoding (DALE-E), andStable Diffusion are also being used to create Synthetic Data.
GPT is an ML model that is used to generate text, and DALE-E and Stable Diffusion are models that are used to generate images. Prompt engineering is helping organisations synthesise data to generate bespoke data points, suitable for their use cases.
How Does It Solve The Above Problems?
Considering the problems from the first section one by one, we see how Synthetic Data can be used to confront these issues.

Privacy Issues

Changing Conditions

Biassed Datasets
Although due to regulatory and ethical reasons, we can’t train our models on personal data where individuals can be identified, using Synthetic Data in the way described above to create artificial replacement data while removing any issues related to privacy is a key benefit. With advances in LLMs, this is easier and easier to accomplish, especially in areas previously out of reach, such as unstructured documents.
Synthetic data created according to statistical rules can be used to retrain Machine Learning models when they lose effectiveness. This is especially useful if we find ourselves in positions where there is insufficient data to begin with.
Synthetic data, especially with the use of LLMs, can be very effective in generating Synthetic versions of unstructured data where there is a lack of data corresponding to a particular characteristic. Again, this relies on the fact that Synthetic versions of data are as effective as real versions for machine learning training purposes. Synthetic data can be used to overcome real-life biases, rather than reinforcing a damaging status quo, counterproductive to the success of many businesses.
Use Case and Benefits
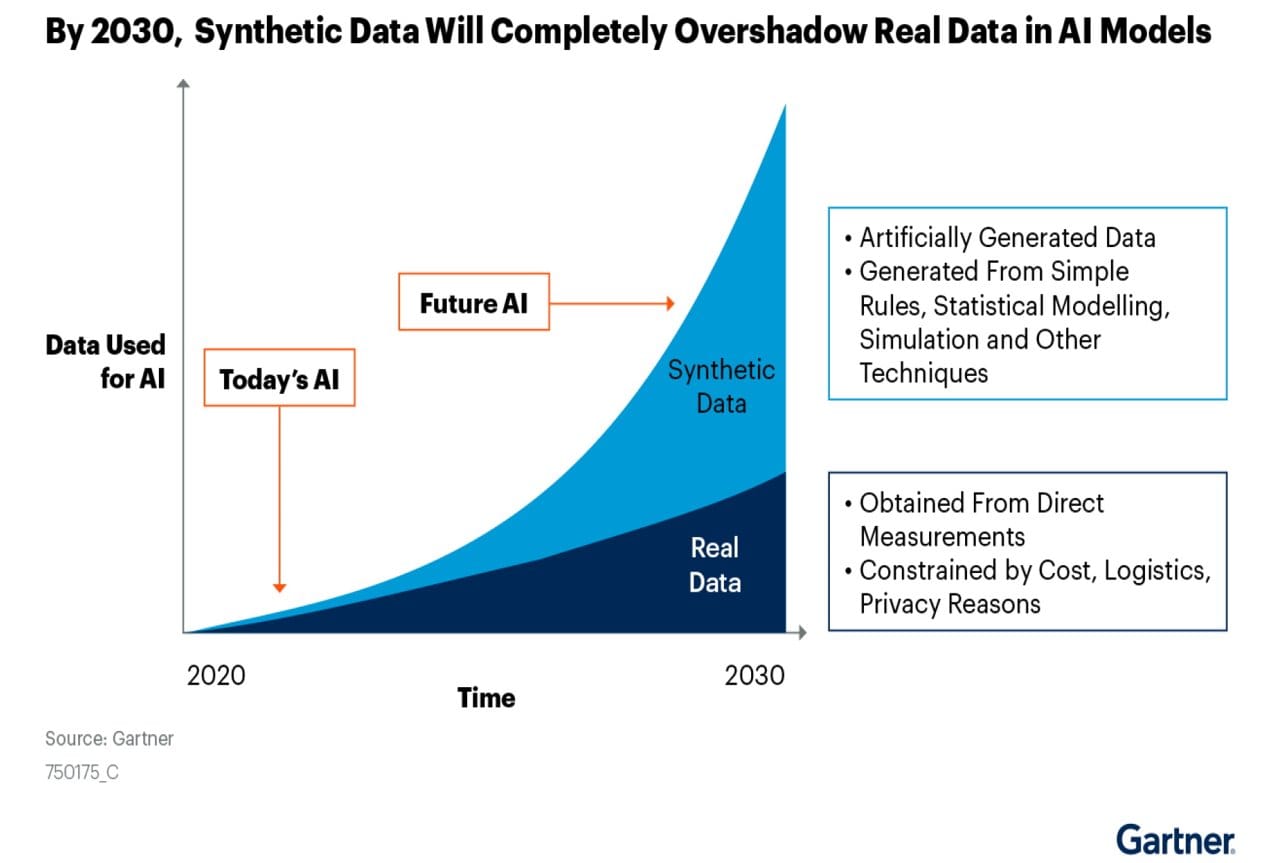
The market potential for synthetic data is growing as the need for large amounts of high-quality data for training machine learning models and other uses increases.
“Gartner estimates that by 2030, synthetic data will completely overshadow real data in AI models.” – Gartner, June 2022
We consider all major industries which are ripe for the use of Synthetic Data to help solve business problems. Here, Synthetic data generation has more specific use-cases - we describe some of them industries here. Within Finance, whether that be in banking, insurance, or any other related sector there are many different opportunities to make use of Synthetic Data.
We give a few use cases:
Synthetic Data in Finance:
Extreme event modelling: One of the biggest problems in risk management is working out the effects of highly unusual events. Whether that would be the financial crisis of 2007-8, or more recently in Covid, working out the effects on people and business is paramount to the riskiness of lending to these clients. The synthetic creation of transaction data is an incredibly powerful tool as we are then able to train our models with this additional data.
Fraud Detection: Using generative adversarial networks, a form of Synthetic Data generation, we are able to create datasets that are importantly balanced - this enables classification models to work with a far greater efficiency than otherwise the case.
Synthetic Data in Retail:
Dynamic Content Generation: Synthetic Data can be used to generate content (i.e marketing, social media etc) that can be tailored to the needs of each consumer group. Thus helping retailers provide a more personalised experience to their customers and more importantly increase customer engagement.
Behaviour Analysis for Next action: Synthetic Data can be used to simulate known or specific customer behaviour and preferences, enabling retailers to develop models which tailor the retailer’s next action specifically to the individual customer.
How Data Reply is Innovating with Synthetic Data?
Data Reply has been at the forefront of innovation using Synthetic Data. We have created a number of solutions addressing some of the most common problems organisations are facing today which we believe synthetic data can help to address.


Prompt: [Input Image] + "Add a Men & Women crown lid on a perfume bottle"
Synthetic Images: Generating synthetic images for design testing
Creating customised designs for products can be a time-consuming and costly process for organisations. Through the use of Stable Diffusion, we were able to generate new designs for perfume bottles based on a single input of an existing picture and a descriptive text prompt without altering the contextual image through masking. This is a huge advantage for companies as it provides them with a competitive edge over market competitors and optimises operational efficiency to innovate and ideate. As a result, organisations can now quickly innovate and ideate on their design process, resulting in faster product-to-market.
Synthetic CV: Unconscious bias mitigation in recruitment through Synthetic Data
Throughout the corporate world, there have been struggles to improve the representation of non-majority groups of people to closer align with the distribution of kinds of people in the real world. For example, as previously mentioned in this post, there have been strong efforts to increase the number of women in C-level positions over the past decades, with mixed levels of success.

Conclusion and Further Innovation
Based on our current research and discussions with industry experts who have concerns in the areas of higher risk, lower data availability, and simulation, Data Reply has concluded that synthetic data, when approached correctly and coupled with sophisticated technologies, can significantly support businesses in achieving cost-effectiveness, operational efficiency, enhanced performance, risk simulation, privacy, and bias mitigation. Data Reply continues to both research and collaborates with clients to support them through synthetic data.
Key focus areas include:

Data Anonymisation and moderation

Data Synthesis and Augmentation

Synthetic Data for better ML models

Simulation for Safety and Risk

Data Reply is a Reply Group company, a premier AWS partner, offering a broad range of advanced analytics, AI ML and data processing services. We operate across different industries and business functions, enabling our customers to achieve meaningful business outcomes through effective use of data, accelerating innovation and time to value.