SOM per segmentazione della clientela
La segmentazione della clientela è uno dei campi di applicazione delle SOM nel settore CRM. L’elemento chiave nel CRM e nella segmentazione dei clienti è l’informazione generale sui clienti. Oggi i dati sui clienti sono prontamente disponibili tramite ERP, data warehouse aziendali e internet. Il problema è che la quantità di informazioni disponibili per la segmentazione è enorme e può essere molto impegnativa da gestire. Perciò, l’estrazione delle informazioni provenienti da grandi database è spesso eseguita utilizzando metodi di data mining.
In questo contesto, le SOM costituiscono uno strumento molto utile sia nella fase di exploratory data analysis (EDA) sia nella vera e propria fase di segmentazione, il clustering. In EDA, le SOM consentono di visualizzare sulla mappa le caratteristiche dei consumatori prima di effettuare il clustering: è possibile valutare già in fase esplorativa quali consumatori sono simili e quali caratteristiche li rendono simili. Il clustering viene effettuato sui codebook stimati dalle SOM ed identifica dei gruppi le cui caratteristiche possono essere facilmente estratte dall’osservazione della mappa. Questo approccio, calcolo delle SOM e clustering dei codebook delle SOM, viene chiamato “a due livelli”.
Quindi, utilizzare le SOM per la profilazione e la segmentazione della clientela fornisce due principali vantaggi:
- Osservando la mappa si possono facilmente visualizzare e comprendere le caratteristiche dei clienti analizzando le caratteristiche dei codebook che formano la mappa.
- Organizzando i clienti in una SOM vengono clusterizzati i codebook e non i dati di input. I dati di input vengono, quindi, associati al cluster assegnato al proprio BMU. In questo modo è possibile esplorare le relazioni tra i raggruppamenti generati dall’algoritmo di clustering.
Vediamo di seguito le analisi e i risultati dell’algoritmo SOM applicati a dei dati di vendita di un supermarket (vedi dataset Kaggle).
Il dataset originale è stato ristrutturato in modo tale da avere per ciascun cliente:
- Spesa media per transazione
- Quantità media di prodotti acquistati per transazione
- Range di età
L’algoritmo SOM supporta solo valori numerici, perciò è necessario codificare le variabili categoriali. In questo esempio, per ciascun range di età è stata creata una variabile dummy (1 = cliente appartiene a quel range di età, 0 = altrimenti).
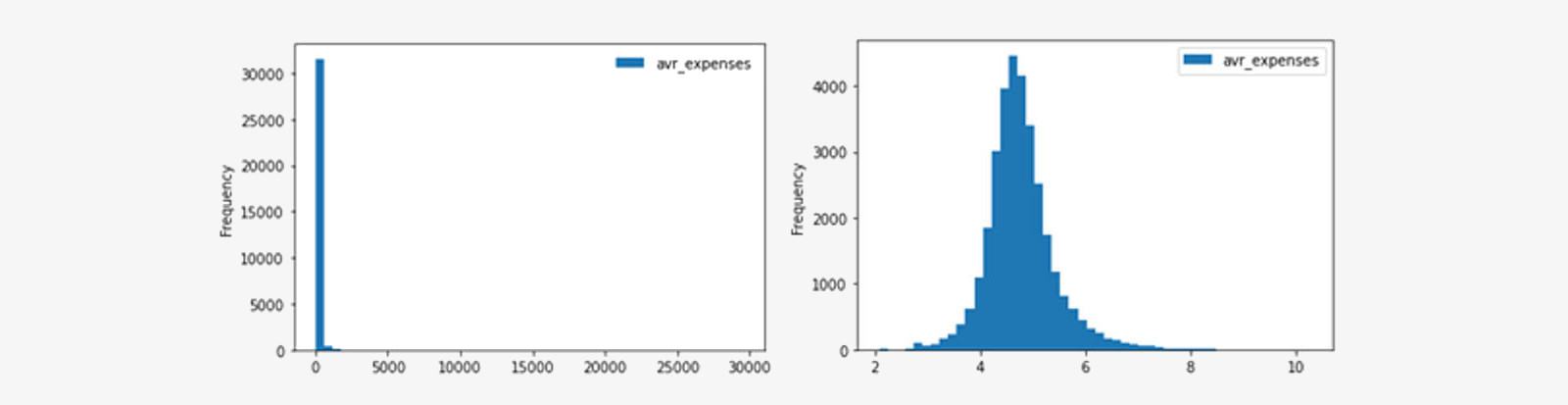
Inoltre, l’algoritmo è molto sensibile alla presenza di outliers: è importante verificarne la presenza e ridurne l’impatto. In questo esempio, le distribuzioni delle variabili spesa media e quantità media di prodotti acquistati sono molto distorte a causa della presenza di outliers, perciò sono state trasformate con una funzione logaritmica.
Ora è possibile iniziare il training della SOM con i dati ristrutturati e trasformati. La mappa originata contiene i codebook stimati, allocati in modo tale che codebook simili (vicini secondo la distanza euclidea) si trovino vicini sulla mappa 2-D.
Alcuni codebook:

La dimensionalità del vettore codebook è pari alla dimensionalità del dataset di input. Weight_2 – weight_11 sono i pesi relativi alle variabili dummy generate a partire da range età.
Sulla mappa è possibile visualizzare la distribuzione dei codebook relativi a ciascuna variabile. Ispezionando le distribuzioni è possibile individuare pattern (aree colorate) che descrivono il comportamento dei consumatori.
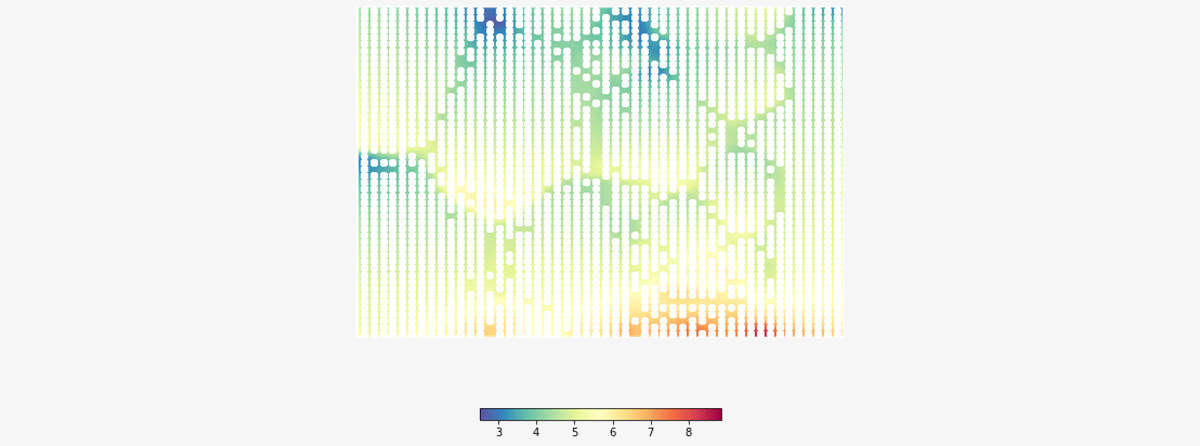
Nella seguente figura è riportata la SOM colorata rispetto ai pesi dei codebook relativi alla variabile spesa media (weight_0). I punti bianchi sono i codebook stimati:
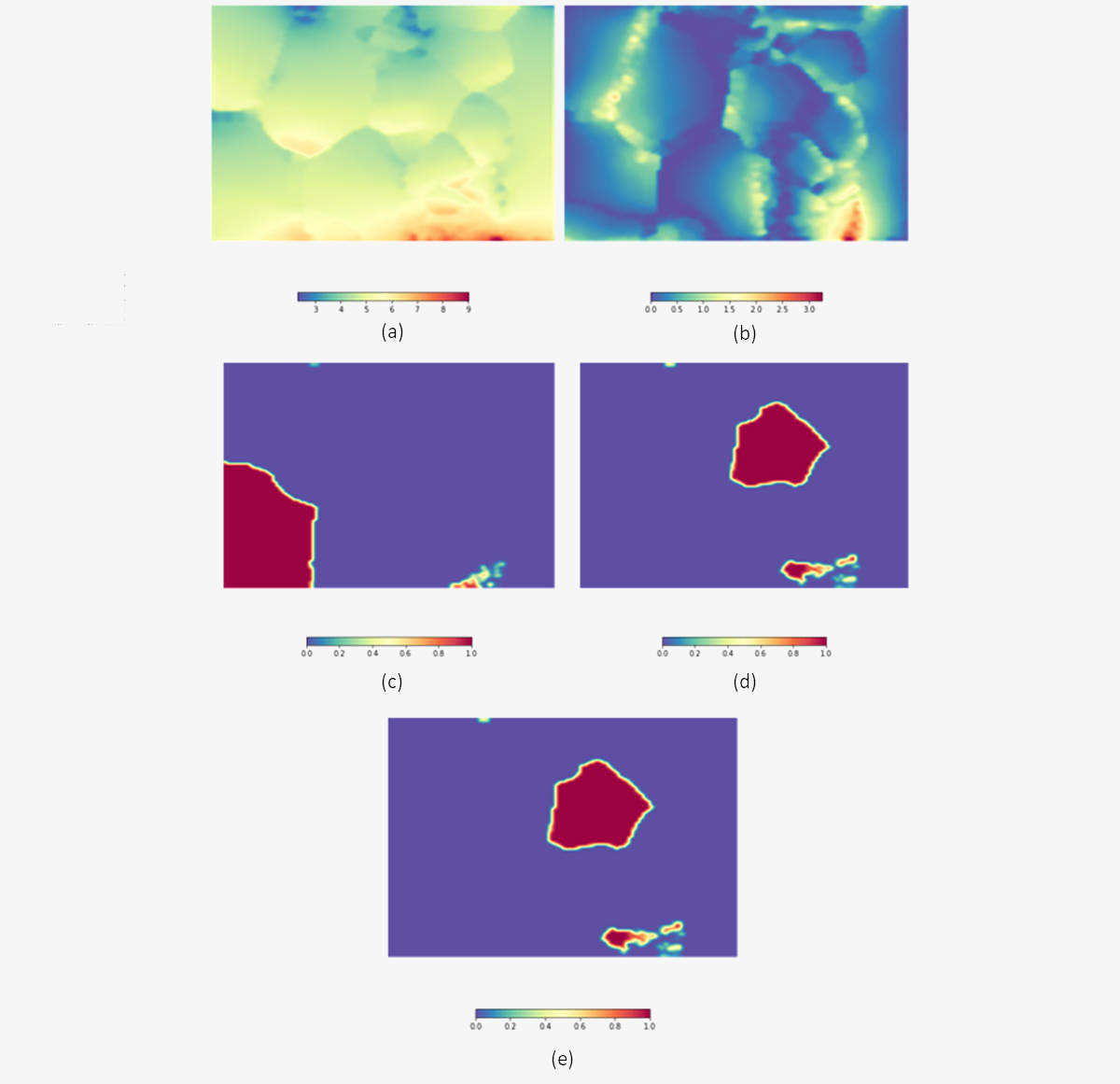
Nella figura sottostante, invece, la SOM è stata colorata secondo i pesi dei codebook relativi rispettivamente alle variabili (a) spesa media, (b) numero medio di prodotti acquistati, (c) range età 25-29, (d) range età 30-34, (e) range età 50-54. Si evince che in basso a destra si distribuiscono dei consumatori che spendono e acquistano molto ed hanno età compresa tra 50-54 anni e tra i 30 – 34 anni. Consumatori tra i 20-25 anni non spendono e non acquistano molto e sono collocati vicino ai consumatori tra i 30-34 anni. Infatti, la maggior parte dei consumatori nel range 30-34 ha spesa media e numero medio di acquisti non elevati, solo un piccolo gruppo rientra tra i consumatori “più attivi” citati sopra.
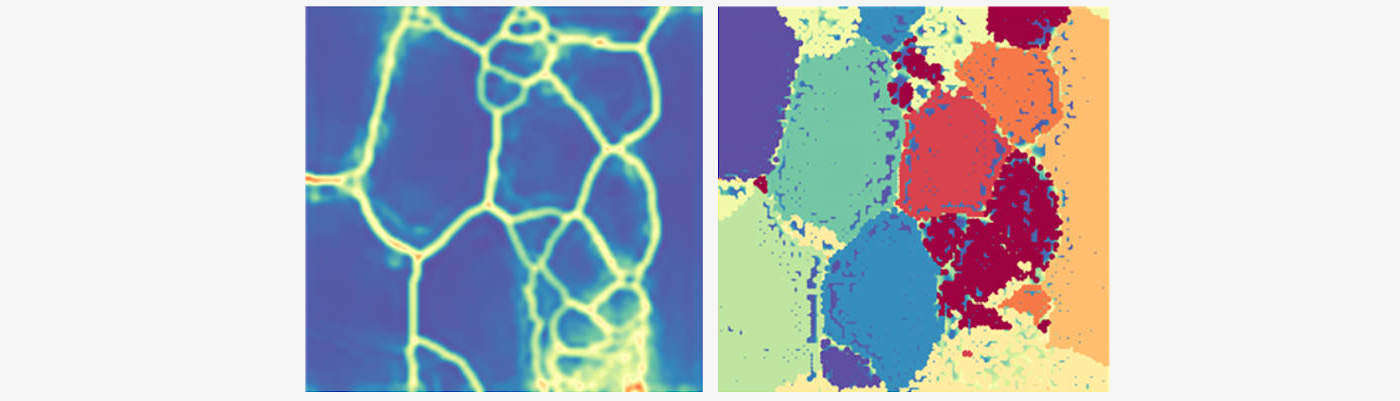
In seguito al training della SOM, è possibile visualizzare la U-Matrix dei codebook: la distanza euclidea tra i codebook è rappresentata in una scala di grigi o bicromatica in un’immagine 2-D . Il salto cromatico (rappresentato dal giallo nella figura sottostante a sinistra) indica codebook distanti, mentre l’altro colore più uniforme (in questo caso il blu) indica codebook vicini.
Infine, applicando un algoritmo di clustering sui codebook è possibile ottenere e visualizzare cluster di consumatori, come nella figura sottostante a destra.